
您的位置:主页 > 公告动态 > 国王金融动态 > 国王金融动态
薛定谔的 AI 大模子:箱子暂不能打开,但钱还要
电风扇与空皂盒的故事,人人都听过吧?
听说某国际着名快消大厂曾引进一条香皂包装生产线,效果发现这条生产线在包装香皂的历程中泛起了一个缺陷,就是经常有盒子没装入香皂。总不能把空盒子卖给主顾,于是,他们就请了一个学自动化的博士厥后设计分拣空香皂盒的方案。
该博士后立刻召集了一个十几人的手艺团队,综合接纳机械、自动化、微电子、X射线探测等等手艺,破费 90 万,最后乐成地研究出了一个方案,就是在生产线的两旁安装两个集成探测器,每当检测到有空香皂盒经由,就会驱动一只机械手将空皂盒推走。
可以说,这是一次手艺落地解决现实产业问题的主要突破。
巧合的是,与此同时,中国南方某州里企业也购置了同样的生产线。老板发现这个问题后,十分火大,叫来工厂的一名小工说:「你来想想设施解决这个问题。」迫于压力,小工很快就想出了一个奇策:他花 190 元买了一台大功率电风扇放在香皂包装生产线的旁边,产线一转就最先猛吹,空的香皂盒一泛起,就被吹走了。
小工一人,依附机智的创意,迅速解决了这个问题,实现了业界常吹说的一个大目的:降本增效。
科技刷新,智能在产业中的涵义无非就是这两个口号:一是省钱,二是增效。然而,在近几年的 AI 生长中,却泛起了这样一个貌似违反资源纪律的「怪异」征象:不管是学术界照样工业界,不管是大公司照样小公司,不管是私企照样国家资助的研究院,都在花大价钱「炼」大模子。
导致圈内有两种声音:一种声音说,大模子已在多种义务基准上展现出壮大的性能与潜力,未来一定是人工智能的生长偏向,此时的投入是为未来不错过时代大时机做准备,投入成百上万万(或更多)训练是值得的。换言之,抢占大模子高地是主要矛盾,高成本投入是次要矛盾。
另一种声音则说,在 AI 手艺落地的现实历程中,当前对大模子的周全吹嘘不仅抢夺了小模子与其他 AI 偏向的研究资源,而且由于投入成本高,在解决现实的产业问题中性价比低,也无法在数字化转型的大靠山中造福更多的中小企业。
也就是说,「经济可不能用」与「能力强不壮大」组成了 AI 算法解决现实问题中的两大焦点。现在,业界已杀青一个共识:在未来,AI 将成为赋能各行各业的「电力」。那么,从 AI 大规模落地的维度看,大模子与小模子哪一个更好?业界真的想好了吗?
01、「大」模子到来
近年来,海内外的科技大厂在对外宣传 AI 研发实力的声音中,总有一个高频的词汇泛起:大模子(Big Model)。
这场竞争最先于外洋的科技巨头。2018 年谷歌推出大规模预训练语言模子 BERT 拉开大模子的帷幕后,OpenAI相继于 2019 年与 2020 年推出 GPT-2、GPT-3;2021 年,谷歌又不甘落伍,推出在参数目上压倒前者的 Switch Transformer……
所谓模子的巨细,主要的权衡指标就是模子参数目的规模。模子的「大」,指的就是重大的参数目。
例如,BERT 的参数目在2018年*到达 3 亿参数目,在机械阅读明晰*水平测试 SQuAD1.1 的两个权衡指标上周全逾越人类,并在 11 种差其余 NLP 测试中到达 SOTA 显示,包罗将 GLUE 基准推高至80.4% (*改善7.6%),MultiNLI准确度到达86.7% (*改善5.6%),展示出了参数目增大对 AI 算法性能提升的威力。
OpenAI 先后推出的 GPT-2 参数目到达 15 亿,GPT-3 的参数目*突破千亿,到达 1750 亿。而谷歌在 2021 年 1 月公布的 Switch Transformer,更是*到达万亿,参数目为 1.6 万亿。
面临这如火如荼的事态,海内大厂、甚至政府资助确立的研究机构也纷纷不甘落伍,先后推出他们在炼大模子上的功效:2021年4月,阿里达摩院公布中文预训练语言模子「PLUG」,参数目 270 亿;4月,华为与鹏城实验室团结公布「盘古α」,参数目 2000 亿;6月,北京智源人工智能研究院公布「悟道2.0」,参数目 1.75 万亿;9月,百度公布中英双语模子 PLATO-X,参数目百亿。
到去年 10 月,阿里达摩院公布「M6-10T」,参数目已经到达 10 万亿,是中国现在规模*的 AI 大模子。虽然比不上阿里,但百度在追求模子的参数目上也不甘落伍,团结鹏城实验室公布了「百度·文心」,参数目 2600 亿,比 PLATO-X 大了 10 倍。
腾讯也称他们研发了大模子「派大星」,但参数目级不明。除了普遍受人人关注的 AI 研发大厂,海内的大模子研发主力中还包罗了算力提供商浪潮,他们在去年 10 月公布了大模子「源1.0」,参数目到达 2457 亿。总而言之,2021 年可以称为中国的「大模子元年」。
到今年,大模子继续火热。最最先,大模子是集中在盘算语言领域,但现在也已逐渐拓展到视觉、决议,应用甚至笼罩卵白质展望、航天等等重大科学问题,谷歌、Meta、百度等等大厂都有响应的功效。一时间,参数目低于 1 亿的 AI 模子已经没有声量。
毫无疑问,无论是性能逾越照样义务拓展,AI 大模子都展示出了内在的潜力,给学术界与工业界带来无限的想象空间。
有研究实验注释,数据量与参数目的增大能够有用提升模子解决问题的正确度。以谷歌2021年公布的视觉迁徙模子 Big Transfer 为例,划分使用 1000 个种其余 128 万张图片和 18291 个种其余 3 亿张图片两个数据集举行训练,模子的精度能够从 77% 提升到 79%。
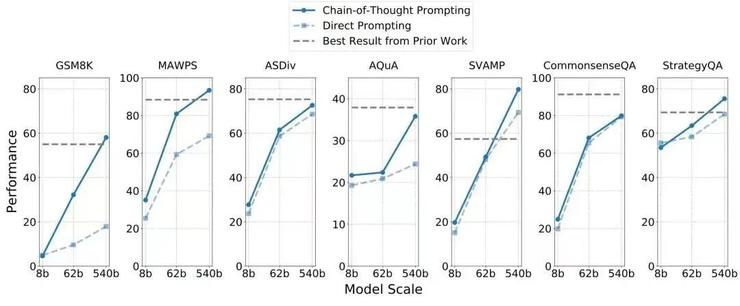
再拿今年谷歌推出的 5400 亿参数单向语言模子 PaLM 来说,它基于谷歌今年公布的新一代 AI 框架 Pathways,不仅在微调方面逾越了 1750 亿参数的 GPT-3,而且推理能力大幅提升,在 7 个算术应用题/知识推理数据集上,有 4 个逾越了当前的 SOTA(如下表),而且只用了 8 个样本(即采集的数据)。
视觉即感知,语言即智能,但两者在「因果推理」的攻克上一直没有太耀眼的突破,而因果推理这一项能力对 AI 系统的进化又十分主要。可以这样明晰:小孩子能够凭证 1 1=2 来得出 100 100=200 的简朴能力,对机械系统来说却十分庞大,就是由于系统缺少因果推理的想象力。若是机械团结理的推理能力/想象力都没有,那么我们距离研发出科幻影戏里智能超群的机械人将遥不能及。而大模子的泛起,使通用人工智能(AGI)的实现成为可能。
以是,我们可以看到,大公司宣传一个大模子,往往强调它能够同时解决多项义务,在多个义务基准上到达 SOTA(当前*水平)。好比,谷歌今年推出的 5400 亿参数语言大模子 PaLM 可以解读笑话,还可以通过emoji神色猜影戏,智源推出的「悟道2.0」可以孵化出琴棋字画、样样醒目的虚拟学生华智冰。
简而言之,大模子往往具备一个特征:多才多艺,身兼多职。这对解决庞大场景的挑战至关主要。
「小模子的参数目少,局限于单一义务;而大模子(的优势)就像是,人在学习打乒乓球时所学到的知识对打羽毛球是有辅助效应的。大模子的义务与义务之间有泛化性。面临新义务时,小模子可能需要几千个、几万个训练数据,而大模子需要只可能一个训练数据,甚至完全不需要训练数据。」西湖大学深度学习实验室的卖力人蓝振忠向雷峰网-AI 科技谈论注释。
以对话系统的研究为例。对话系统主要分为两大类:一类是义务型对话,用户下达义务、AI 系统自动执行,快速订机票、买影戏票等等;一类是开放型对话,如影戏《她》(Her)中虚构的机械人,能够与人类交流任何话题,甚至让用户感受到情绪上的陪同。这其中,后者的能力品级显然更高,研举事度也更大。前面迷雾重重,你不清晰将会晤临怎样的挑战,这时,大模子自己具备的厚实「能力包」和在新义务上超常的精彩显示,战斗力显然要优于小模子。
蓝振忠指出,现在学术界与工业界的 AI 研究者们对于大模子的许多特征还未完全掌握。举个例子,从上一代的 GPT-3 到这一代的 instruct GPT,我们可以看到它有一个质的飞跃,同样是大模子,然则 instruct GPT 在接受下令时效果却好许多,这是他们在研究大模子时才气体验到的。
参数目越来越大,AI 模子的性能事实会发生什么转变?这是一个需要深入探索的科学问题,因此,继续投入研究大模子是有需要的。
02、理想很远,现实很近
人类要提高,就总要有人勇往无人之境。
然而,在现实天下中,并不是每小我私人都能肩负得起星辰大海的理想,更多的人只想以多快好省的方式解决眼前所面临的问题。归根结底,AI 算法要落地,就必须思量手艺研发的投入产出比。这时,大模子的坏处就最先露出。
一个不容忽视的残酷事实是:大模子的盘算慢,训练成本极高。
通常来说,模子的参数目越大,机械跑得越慢,盘算成本也越高。据外媒披露,OpenAI 在训练包罗 1750亿参数的 GPT-3 时花了靠近 500 万美元(人民币约 3500 万)。谷歌在训练包罗 5400 亿参数的 PaLM 时用了 6144 块 TPU,据热心网友统计,通俗人训练一个 PaLM 的成本在900至1700万美元之间。这还仅仅是算力的用度。
海内各大厂没有披露过它们训练大模子的经济成本,但凭证现有全球共享的盘算方式与资源来看,盘算支出应当相差不远。GPT-3与PaLM都还仅是千亿级数目,而参数目到达万亿级以上的大模子,其成本投入想必惊人。若是一家大厂对研发足够阔绰,大模子的投入成本便不是一个「拦路虎」,但在当前资源对 AI 越发郑重之际,一些创业公司与政府投资的研究机构还鼎力下注大模子,这就显得有些魔幻了。
大模子对算力的高要求,使企业间的手艺实力竞争酿成了款项的竞争。从久远来看,一旦算法成为高消费商品,就注定最前沿的 AI 只能为少数人享有,从而造成围城圈地的垄断事态。换言之,纵然有一天,通用人工智能真的泛起,也无法造福所有用户。
同时,在这一赛道上,小企业的创新力将被挤压。要炼成大模子,小企业要么与大厂相助、站在巨人的肩膀上(但这也并不是每一家小厂都能做到的事情),要么狂拉投资、备好金库(但在资源的隆冬中,这也不切现实)。
算完投入,再算产出。遗憾的是,现在还没有一家在炼大模子的企业披露过大模子缔造了多大的经济效益。不外,从果然信息中可以得知,这些大模子已经最先陆陆续续落地解决问题,如阿里达摩院在公布万亿参数模子 M6 后,称其图像天生能力已经可以辅助汽车设计师举行车型设计,借用 M6 的文案天生能力所创作的文案,也已经在手机淘宝、支付宝和阿里小蜜上获得使用。
对于正处于探索起步阶段的大模子来说,强调短期回报未免苛刻。然而,我们仍然要回覆这样一个问题:无论是企业界照样学术界,在下注大模子时,是为了不错过一个可能在未来占有主导职位的手艺偏向,照样由于其能更好地解决眼前已知的问题?前者有粘稠的学术探索色彩,尔后者则是产业先锋应用 AI 手艺落地解决问题的群体所真正体贴的问题。
大模子由谷歌公布 BERT 拉开序幕起,是一种混沌天开的思绪:在 BERT 实验之前,谷歌大脑的手艺团队并不是围绕一个已知的现实问题来开发模子,也没有想到这个那时参数目*( 3 亿)的 AI 模子能带来效果的大幅提升。同理,OpenAI 在模拟谷歌开发 GPT-2 与 GPT-3 时,也没有一个特定的义务,而是乐成开发出来后,人人在 GPT-3 上测义务效果,发现各项指标都有所提升,才被惊艳到。现在的 GPT-3 就像一个平台,已被用户搭载了成千上万个应用。
但随着时间的推移,大模子的生长照样不能制止地回到领会决某一个现实问题的初衷,如 Meta 今年公布的卵白质展望大模子 ESMFold,百度不久前公布的航天大模子。若是说一最先的 GPT-3 等大模子主要是想探索参数目增大会对算法的性能改变带来什么影响,是纯粹的「未知指导未知」,那么现在的大模子研究则最先体现出一个较为清晰的目的:就是要解决现实问题,创业价值。
这时,大模子的生长指导方,就从研究者的意志转换为了用户的需求。在一些十分细小的需求(如车牌识别)中,大模子也能解决问题,但由于其昂贵的训练成本,未免有点「杀猪焉用牛刀」的意味,且性能纷歧定精彩。或者说,若几个点的精度提升是靠上万万的成本换来的,性价比就显得极低。
一位业内人士就告诉雷峰网-AI 科技谈论,在绝大多数的情形下,我们研究一项手艺是为领会决某一个已知的现实问题,如情绪剖析、新闻归纳综合,这时我们着实就可以设计一个专门的小义务去研究,出来的「小模子」的效果很容易就比 GPT-3 等大模子要好。甚至在一些特定的义务上,大模子「基本没法用」。
以是,在推动 AI 生长的历程中,大模子与小模子的连系是一定的。而由于大模子的研发门槛极高,在肩负 AI 大规模落地的重任上,在肉眼可见的未来,经济可用、精准袭击的小模子才是主力军。
纵然是一些正在研究大模子的科学家,他们也明确地告诉雷峰网,虽然大模子能够同时推行许多义务,但「现在谈通用人工智能还太早」。大模子或许是实现*目的的一个主要途径,但理想尚远,AI 照样要先知足当下。
03、AI 模子一定要越来越大吗?
事实上,针对 AI 模子越来越大的征象,学术界与工业界的部门研究者已经注重到其在落地中的利与弊,并努力睁开应对之策。
若是要说科技对社会的改变给予了人们怎样的启示,那么其中一定谈判到的主要一条即是:若何降低科技产物的门槛(无论是手艺上照样成本上),让更多的人能够享受到这项科技的利益,才气扩大它的影响力。
换到大模子中,焦点矛盾就是若何提升它的训练速率、降低训练的成本,或提出新的架构。
若是单从挪用盘算资源来看,大模子的逆境现实上并不突出。今年 6 月尾开下班程同盟 MLCommons 公布的 MLPerf 基准最新训练效果显示,今年机械学习系统的训练速率险些是去年的两倍,已经突破了摩尔定律(每18-24个月翻一倍)。
事实上,随着各家服务器的更新迭代,云盘算等新颖方式的泛起,盘算一直在加速,能耗也一直在降低。举个例子,GPT-3 推出仅两年,现在 Meta 参照它所研发的 OPT 模子的盘算量已经降低到了2020年的1/7。此外,最近尚有一篇文章注释,2018 年需要几千块 GPU 训练的大模子 BERT,现在只需要单卡 24 小时就能训练好,一个通俗的实验室也能轻松训练。
获取算力的瓶颈已经不存在,*的拦路虎只是获取成本。
除了单纯依赖算力,近年来,也有一些研究者希望另辟蹊径,单从模子与算法自己的特征去实现大模子的「经济可用性」。
一种途径是以数据为中央的「降维」。
最近 DeepMind 就有一项事情(“Training Compute-Optimal Large Language Models”)乐成探索发现,在盘算量相同的情形下,将模子的训练数据变大,而不是将模子的参数目放大,可以获得比仅仅放大模子更好的效果。
在 DeepMind 的这项研究中,一个充实行使了数据的 700 亿参数模子 Chinchilla 在一系列下游义务的评估中逾越了 1750 亿参数的 GPT-3 和 2800 亿参数的 Gopher。蓝振忠注释,Chinchilla 之以是能够取胜,就是由于在训练时将数据扩大、翻倍,然后只盘算一遍。
另一种途径是依赖算法与架构的创新,将大模子「轻量化」。
微软亚洲研究院前副院长、现澜舟科技首创人周明是这一赛道的追随者。
作为一名创业者,周明的想法很「天职」,就是要省钱。他指出,现在许多大的公司都在追求大模子,一是争先恐后,二是也想体现自己的盘算能力,尤其是云服务的能力。而澜舟科技作为一家降生不久的小公司,有用 AI 缔造价值的梦想,但没有壮大的云能力,钱也不够烧,以是周明一最先想的是若何通过模子架构的调整与知识蒸馏等等方式,将大模子酿成「轻量化模子」给客户使用。
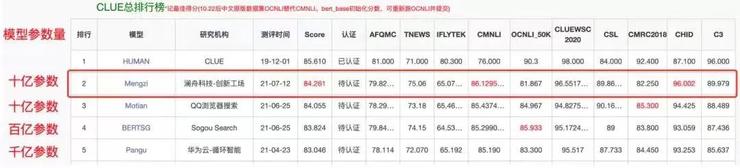
他们在去年 7 月推出的轻量化模子「孟子」证实了该想法的可行性。「孟子」的参数仅 10 亿,但在中文语言明晰评测榜单 CLUE 上的显示却逾越参数目级为百亿甚至千亿的BERTSG 与盘古等等大模子(如下表)。领域的一个共识是:在统一个架构下,模子一定是参数目越大、性能越好,但「孟子」的巧妙之处,就在于架构的创新。
在学术界,不久前,加州大学伯克利分校的马毅教授与沈向洋、曹颖还团结揭晓了一项研究(“On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence”),从理论上剖析了大模子为何越来越大的手艺缘故原由,即深度神经网络本质上是一个「开环」的系统,即用于分类的判别模子和用于采样或重放的天生模子的训练在大部门情形下是离开的,导致对参数的训练效率低下,只能依赖堆参数与堆算力来提升模子的性能。
为此,他们提出的「转变」方式更彻底,就是主张将判别模子与天生模子组合在一起,形成一个完整的「压缩」闭环系统,这样 AI 模子就能够自主学习,而且效率更高、更稳固,在面临一个新的环境中可能泛起的新问题时,顺应性与反映能力也更强。换言之,若是 AI 领域的研究者能够沿着这条蹊径去开发模子,模子的参数目级会大幅缩小,回归到「小而美」的蹊径上,也能实现大模子「解决未知问题」的能力。
在实现经济可用上,甚至尚有一种声音,是主张通过 AutoML 或 AutoAI 的方式来解决模子训练的难度,降低 AI 算法的研究门槛,让算法工程师或非 AI 从业者可以天真凭证自己的需求来打造单一功效的模子,形成无数个小模子,星星之火、可以燎原。
这种声音是从「需求」的角度出发,否决凭空捏造。
举个例子,视觉算法用于识别、检测与定位,其中,识别烟雾与烟火对算法的要求差异,那么他们就提供一个平台或工具,让需求者可以划分快速天生一个识别烟雾与识别烟火的视觉算法,精度更高,也不必追求跨场景的「通用性」或「泛化性」。这时,一个琴棋字画样样醒目的大模子,可以分为无数个划分醒目琴、棋、书、画的小模子,同样也能解决问题。
04、写在最后
再回到电风扇吹空皂盒的故事上。
在 AI 手艺解决现实问题上,大模子与小模子就犹如博士后的自动化方案与小工的电风扇,前者虽然在解决某一个小的问题时显得冗余、粗笨,效果也没有电风扇快速,但险些没有人会否认博士后及其团队所提供的价值,更不能能「祛除」他们。相反,我们甚至可以说出几百个理由来强调手艺研发的合理性。
但在许多时刻,手艺研究者却经常忽略了小工在解决问题上的智慧:从现实问题出发,而不是囿于手艺的优势。从这个角度看,大模子的研究固有*前沿的价值,但也要思量降本增效中的「经济可用」目的。
再回到研究自己,蓝振忠示意,现在大模子的功效虽然有许多,但开源少少,通俗研究者的接见有限,这一点很令人惋惜。
由于大模子没有开源,通俗用户也无法从需求的角度来评价大模子的适用性。事实上,此前在现在少数开源的大模子中,我们曾做过实验,发现语言大模子在明晰社会伦理与情绪上的显示存在极高的不稳固性。
由于不开放,各大厂对自家大模子的先容也是停留在学术的各项指标上,这就形成了类似薛定谔的困局:你永远不知道盒子里有什么,也无法判断它的真假,一句话,什么都是他们说了算。
最后,希望 AI 大模子真的能够造福更多人吧。